Ollama: 自托管LLM的简单方案
这两天心血来潮,看着机箱里面的早就不用来打游戏的显卡,总觉得需要做点什么。碰巧看到Ollama,似乎自托管LLM变得比以往容易了很多。特此尝试并记录一下。文中涉及了Ollama的部署和使用,以及两个UI的使用:Big-AGI和Ollama WebUI。
Ollama是什么
大概可以理解为一个本地运行LLM的Framework或者说Platform。跑起来之后可以很方便的对接一众支持的LLM模型,然后还可以对接一众UI。大概可以理解为一种LLM和UI/app之间的Multiplexer。
 ollama
ollama既然只是一个平台或者说Framework,那么自然还是需要UI和LLM才能运行的。在Ollama的Github page上面已经列出了一些选项,个人也进行了一些尝试,在此记录了一下最近的尝试。
Ollama会expose一个OpenAI compatible的API在11434端口上面,然后一种给ChatGPT做的UI大概只需要一些简单的修改就可以对接Ollma上面的模型了。
至于Ollama支持的模型,自然Meta的llama2是在列的。其他的还有最近挺火的Mixtral 8x7b以及Mistral还有Llava2。
Installation and/or Deployment
Ollama本身提供了一个 ollama command line tool 来管理 service up/down 以及模型的pull and deletion。
安装非常简单,Ollama有个Linux上面安装的文档。
# Download the install script
curl https://ollama.ai/install.sh | sh
# other than the script, use this to install manually
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
# Create a user specifically for runing ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
之后最好把Ollama的服务设置为自动启动的。这个任务自然落到Systemd上面。
写一个systemd的service config: /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
Reload the service config and enable ollama service.
sudo systemctl daemon-reload
sudo systemctl enable ollama
但是到此为止,Ollama目前只会接受来自172.0.0.1的请求。所以如果你像我一样希望在另一个Host上面的跑UI,那么到这一步还不够。要开放所有IP的访问,需要设置Environment variable。
OLLAMA_HOST=0.0.0.0
然而我们需要在Systemd运行的时候把这个Environment variable送进去。在 [Service]下面加上一行:
Environment="OLLAMA_HOST=0.0.0.0"
或者直接把下面两行加在一个新的文件下面 /etc/systemd/system/ollama.service.d/environment.conf:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
之后可以重启一下确保生效
sudo systemctl daemon-reload
sudo systemctl enable ollama
这一切都折腾完了之后,终于可以开始用一用了。
ollama pull llama2
ollama run llama2
这之后就是个command line的UI,可以用来跟UI对话。但是这个UI显然不是很现代,不太方便设置system prompt,以及设置Temperature之类的。这些东西自然还是通过UI来设置最好。
Setup UI
目前本人试用过的两个UI是Big-AGI和OllamaUI。
Big-AGI
Big-AGI,从这个名字看就很有野心。Ollama只是它支持的众多后端的一个。Big-AGI大概是打算整合众多AI后端,达成一种,只要通过Big-AGI,就可以完成任何AI相关工作,的效果。
Big-AGI目前一个小遗憾是没有自己的Authentication。这一点其实也说不准是不是遗憾,有时这种项目如果过于注重多用户,可能也会影响项目发展。个人用户的话可以用Reverse Proxy上面建立一个简单的Access List来限制访客。
enricorosBig-AGI之前没有比较靠谱的Docker Image用(最近更新了)。所以与其折腾Dockerfile,不如直接在LXC上面安装。不过big-AGI的安装需要NPM。
用 apt install在Ubuntu上面的安装NodeJS显然不是一个好主意。如果你不幸跟我一样用了 apt install npm 这类的命令,以下的步骤可以撤销所有的影响。
sudo rm -rf /usr/local/bin/npm /usr/local/share/man/man1/node* ~/.npm
sudo rm -rf /usr/local/lib/node*
sudo rm -rf /usr/local/bin/node*
sudo rm -rf /usr/local/include/node*
sudo apt-get purge nodejs npm
sudo apt autoremove
正确安装最新的版本也比想象中容易。首先是Download the latest tar.xz NodeJS file from https://nodejs.org/en/download/。
tar -xf node-v#.#.#-linux-x64.tar.xz
sudo mv node-v#.#.#-linux-x64/bin/* /usr/local/bin/
sudo mv node-v#.#.#-linux-x64/lib/node_modules/ /usr/local/lib/
# Where #.#.# is the version you downloaded.
# Verify installation using
node -v
npm -v
NodeJS装好之后,事情就好办多了。照着文档做就可以了。
git clone https://github.com/enricoros/big-agi.git
cd big-agi
npm install
npm run build
next start --port 3000
docker compose
最近Big-AGI更新了docker image。同时还可以配合Browserless,达成让LLM阅读指定URL网页内容的功能。
version: '3.9'
services:
big-agi:
image: ghcr.io/enricoros/big-agi:latest
ports:
- "3000:3000"
env_file:
- .env
environment:
- PUPPETEER_WSS_ENDPOINT=ws://browserless:3000
command: [ "next", "start", "-p", "3000" ]
depends_on:
- browserless
browserless:
image: browserless/chrome:latest
ports:
- "9222:3000" # Map host's port 9222 to container's port 3000
environment:
- MAX_CONCURRENT_SESSIONS=10
总体来看还是Docker-compose的部署方案干净整洁。
Connect big-AGI with Ollama
一图就可以解释清楚:
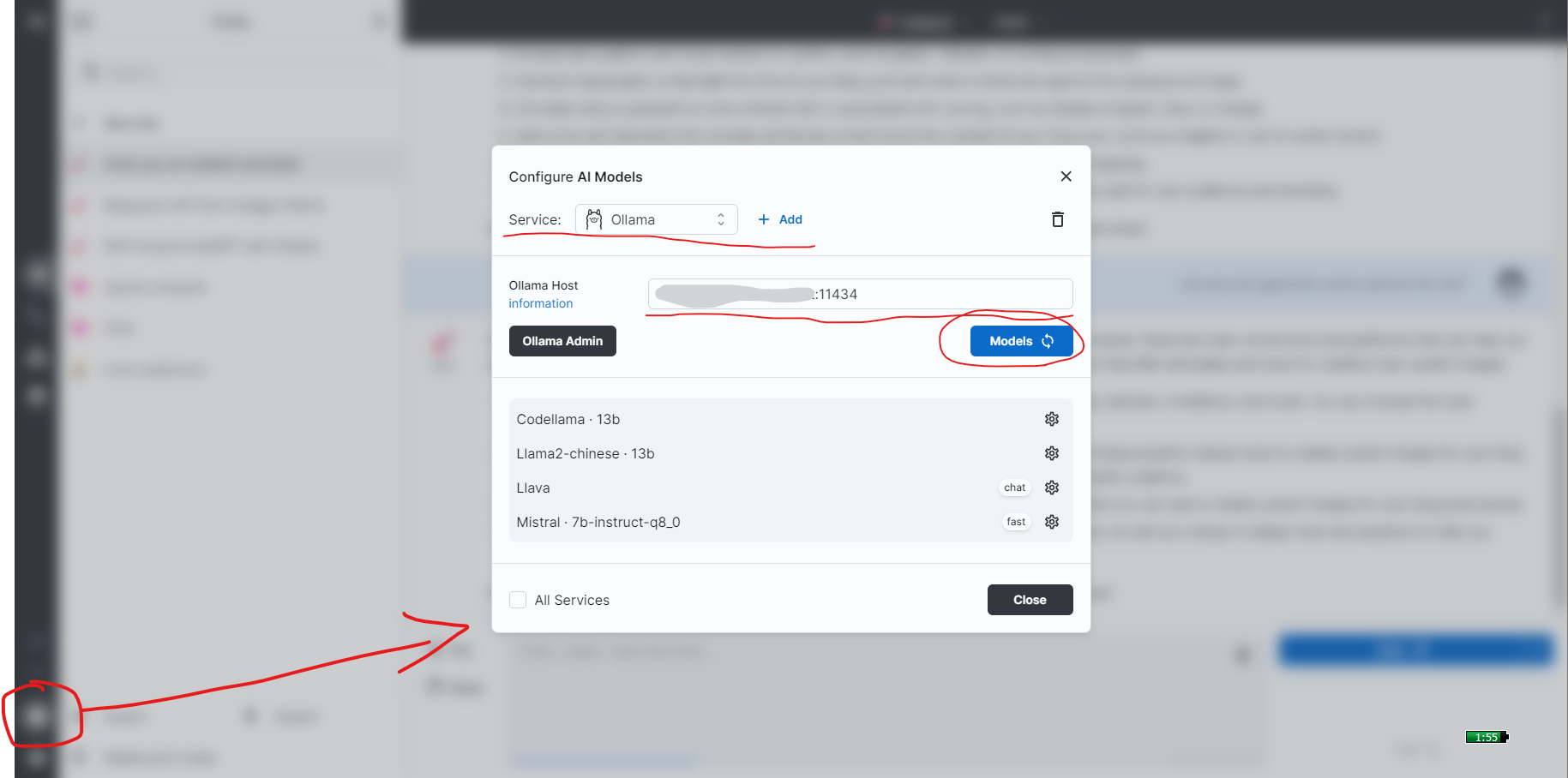
当然,官方也有文档:
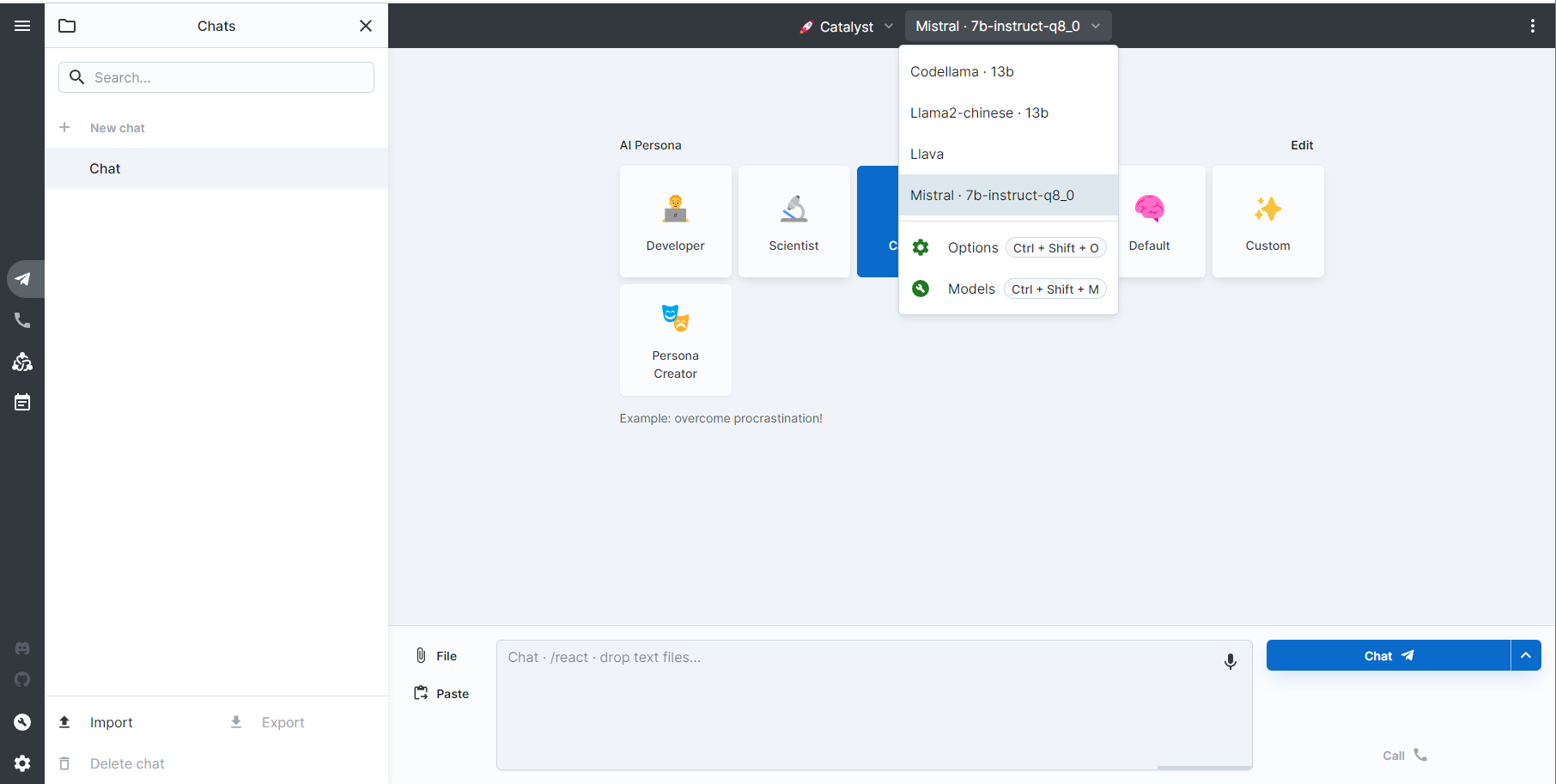
enricorosBig-AGI的使用
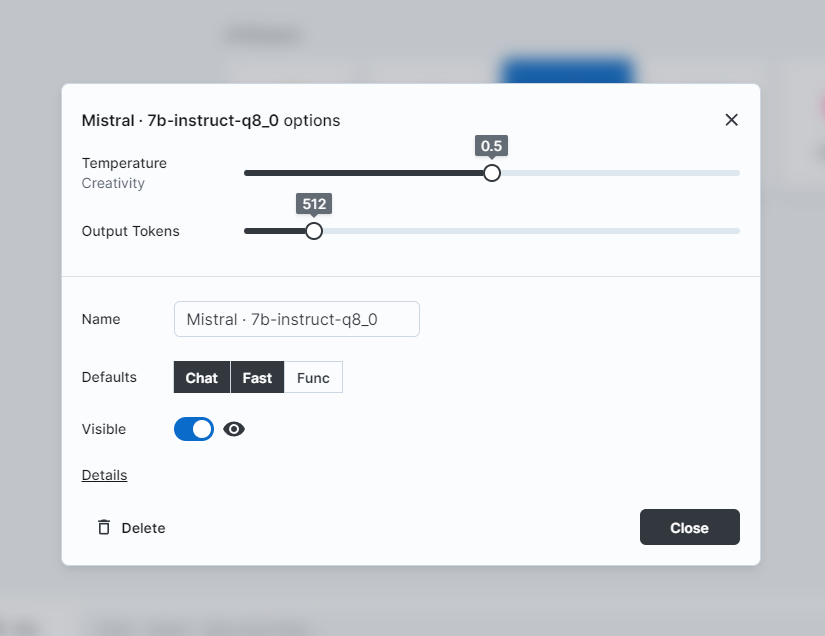
一切就绪之后,在UI里面选择Ollama已经Pull下来的模型。可以考虑调节模型每次的输出token数量以及Temperature:
big-AGI也可以通过Ollama Admin Panel,直接命令Ollama从网上Pull新的模型下来:
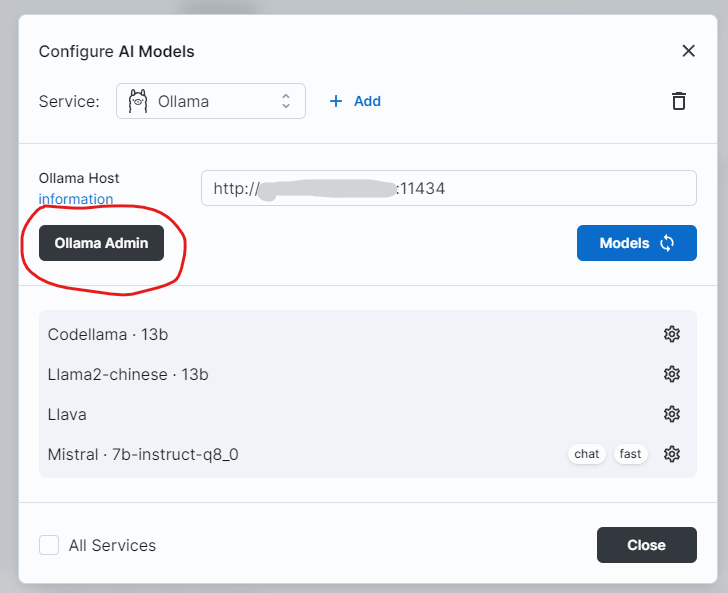
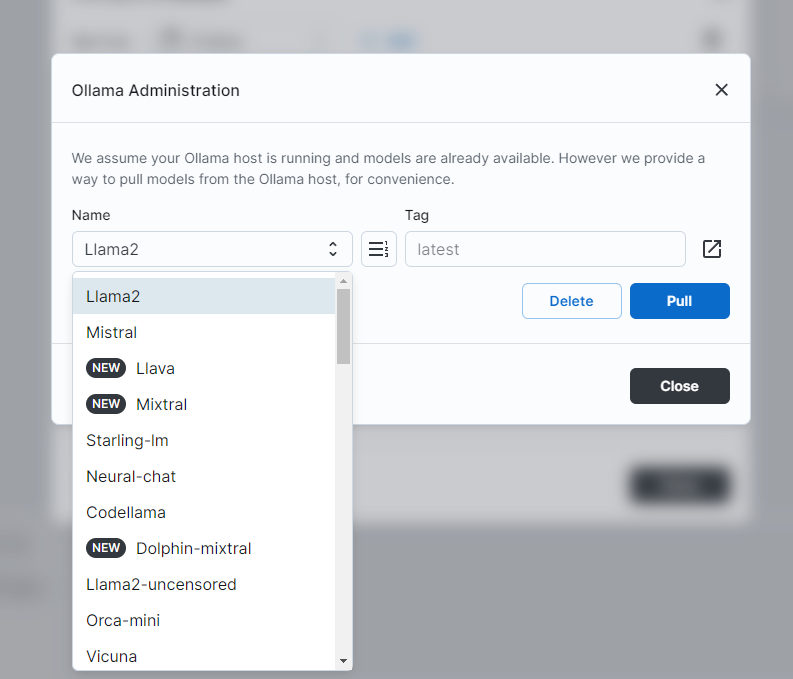
某种意义上讲,这个比Ollama自己的Command line UI还要好用一些。不过pull model这种事情,动辄几个GB甚至几十个GB的文件,还是需要花一些时间的,所以UI就有可能直接timeout。
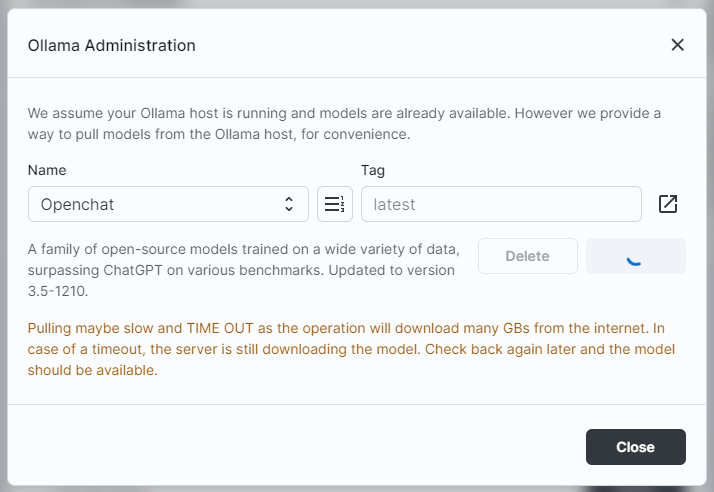
Big-AGI的一个独到之处是,已经预设了一些AI Persona,相当于省去了一些sysem prompt的麻烦,用户大概可以更快的获得想要的内容。比如Developer Persona大概对于代码更加专精,可能有更少的胡编乱造的成分。Catalyst可能更适合写一些博客之类的,也大概会有更多的胡编乱造。Executive也许适合写报告,用词也许会更职业一些。
之后就可以对话了。Big-AGI也支持直接访问麦克风,首先识别语音,转译成文字之后再送到LLM里面去。某种程度上可以达到人机对话的程度。

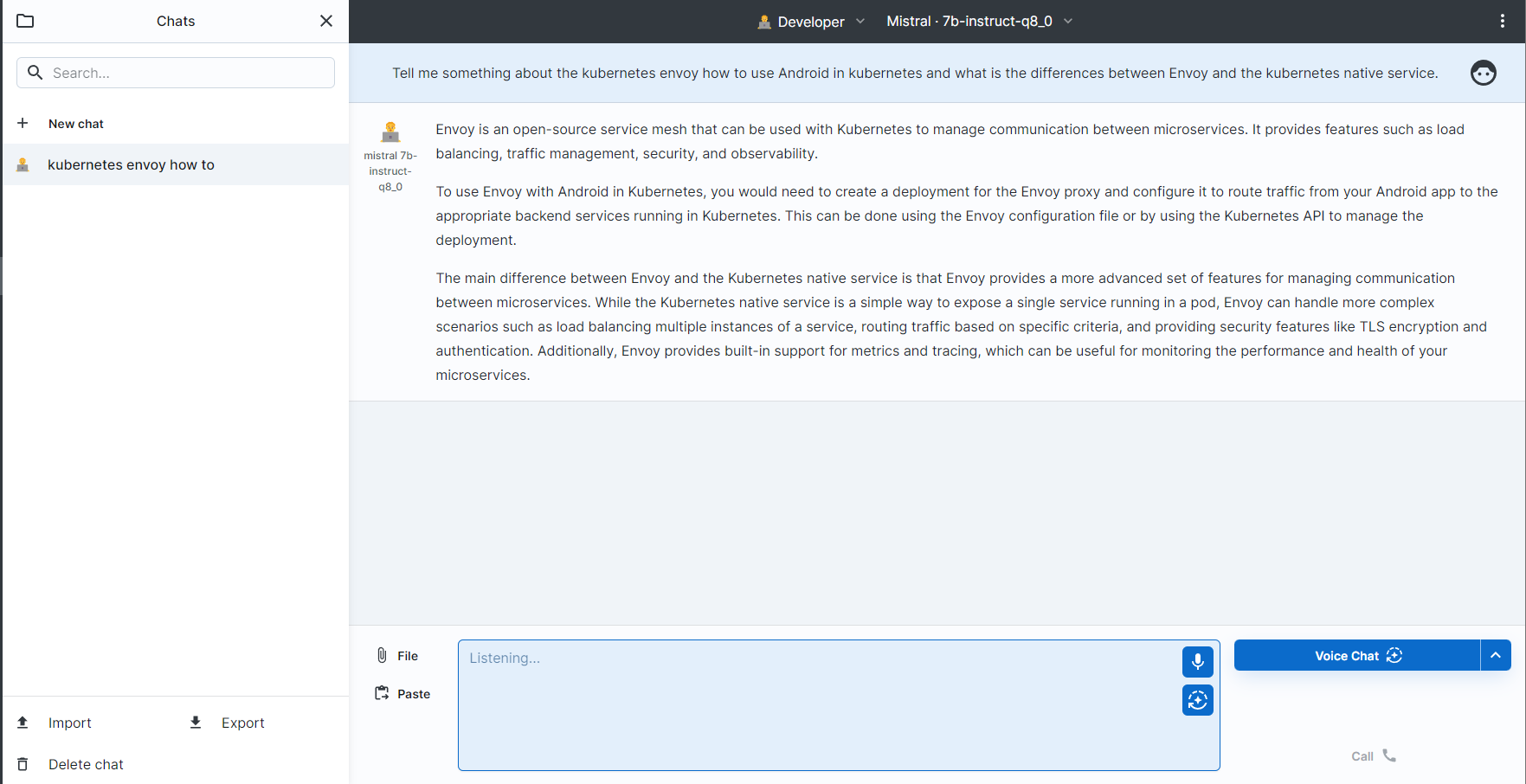
Big-AGI还有很多的功能没有探索,留待日后再谈了。
Ollama WebUI
不同于Big-AGI,Ollama WebUI就是完全面向Ollama设计的。但是其界面是类比了ChatGPT的界面。相比于Big-AGI,这个界面显然是更让人熟悉的。Ollama WebUI也自带了Authentication。
ollama-webui因为Ollama WebUI是给Ollama设计的,所以所谓集成,基本上也只需要Ollama。因此Ollama<>Ollama WebUI的integration就直接通过Environment Variable OLLAMA_API_BASE_URL 的形式给进Ollama WebUI。以下是Docker-compose:
version: '3.8'
services:
ollama-webui:
image: ghcr.io/ollama-webui/ollama-webui:main
container_name: ollama-webui
volumes:
- <path_for_ollama_data_on_your_host>:/app/backend/data
ports:
- 3000:8080
environment:
- 'OLLAMA_API_BASE_URL=http://<you_ollama_IP/hostname>:11434/api'
restart: unless-stopped
第一次登录的时候,可以注册用户。第一个注册的用户就是管理员。
如果是个人用户,一定要记得把新用户注册关上,尽量提高一点安全吧。
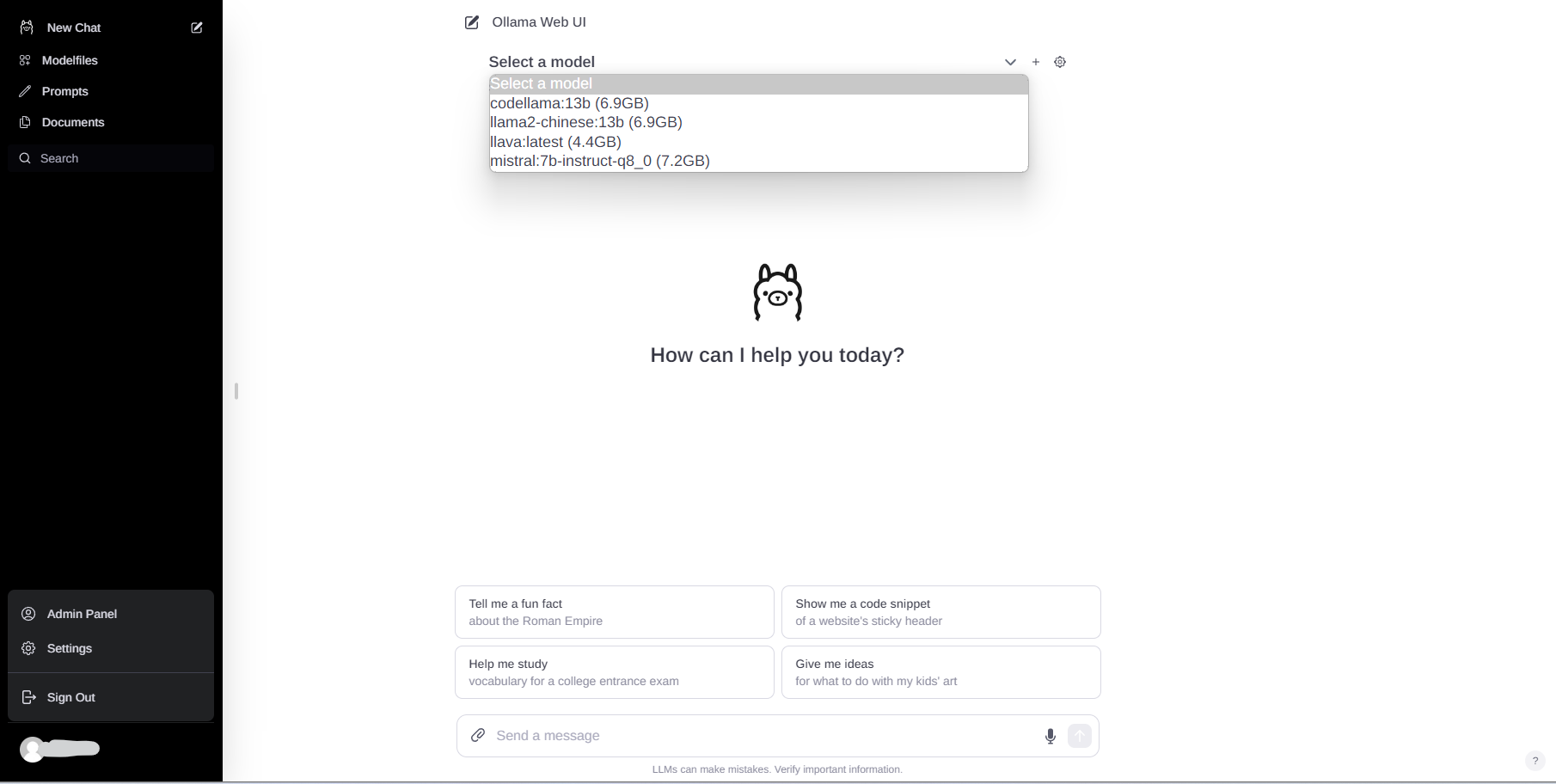
Ollama的使用
首先选择一个模型。
如果没有想要的模型,也可以通过UI直接Pull新的模型下来。
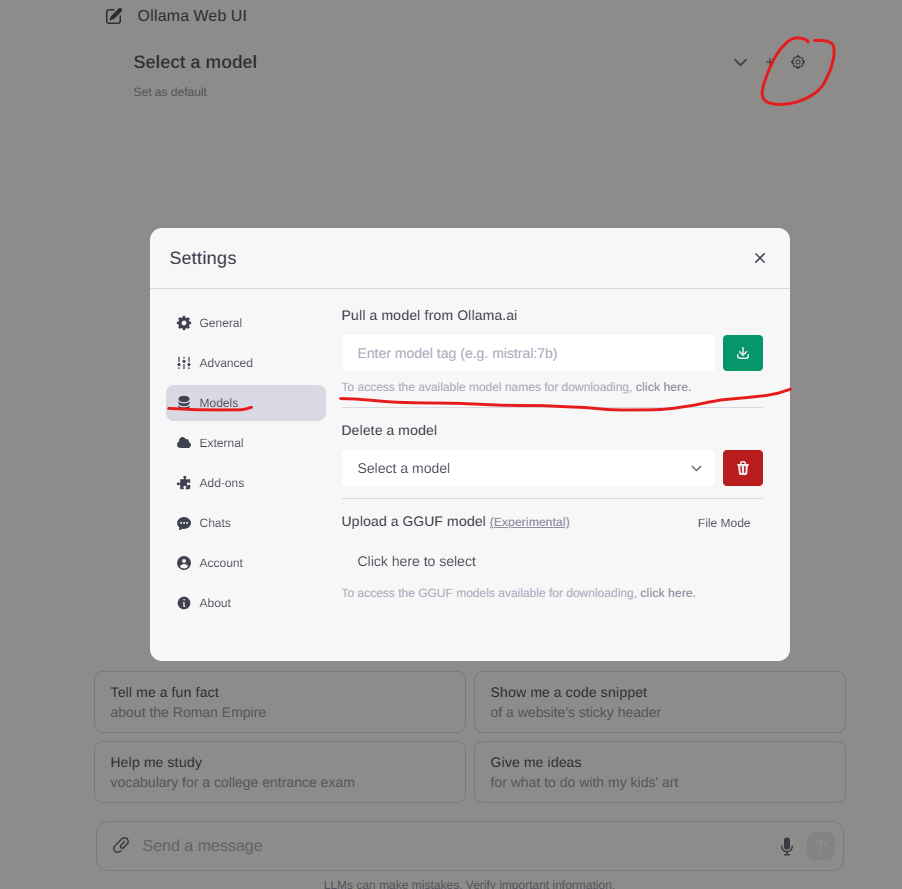
只是比较可惜的是,这里就没有列表可供选择了。我们需要从下面这个链接找模型的名称以及tag。

Ollama-WebUI也提供了麦克风输入方式。不过相比big-AGI,似乎灵敏度查了一点点,也没有自动continue的选项。不过对于很多普通使用场景来讲,已经足够了。
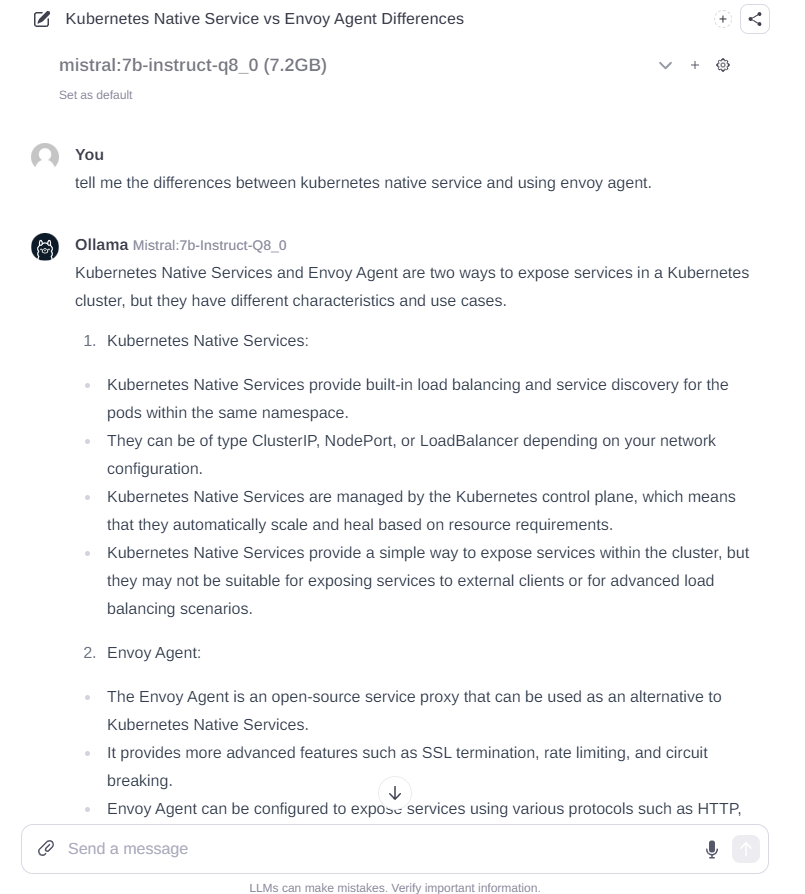
Generated Blog Post
在这个时候我就有点好奇了。用这个LLM生成的文章大概会是什么样子呢?所以我就通过Mistral:7b模型生成了一段文章,我给的要求是,生成一篇关于自托管LLM的文章,要提到自托管的原因,以及使用Ollama运行Mixtral模型的步骤,还有就是要提到使用GPU进行加速。
从文中可以看到,大体的行文是不错的。但是由于模型没有联网自我学习,所以这个文章中充斥着各种幻想出来的东西。并且大概是受制于token的限制,文章的细节也不充足。只能说,在一张小小的3070显卡上面自托管LLM,目前来看,只能当作娱乐。
以下部分就是生成的文字了。
为什么要选择自主托管的LLM?
随着语言模型在深度学习中越来越广泛应用,人们开始注意到 OpenAI 提供的 ChatGPT 虽然强大,但是有些限制。首先,ChatGPT 需要在 OpenAI 服务器上运行,这意味着你无法进行自主托管。其次,使用 ChatGPT 会导致部分数据被收集并存储在 OpenAI 的企业服务器上,这可能会引起一些人的疑问和安全性担忧。因此,使用自主托管的LLM可以解决这些问题。
自我托管LLM的选项
当你想要使用自主托管的LLM时,有许多选项可供选择。其中一个最流行的是 Ollama,这是一个通过 GitHub 开源的 LLaMA(Language Model for All)的自主托管模型。Ollama 支持多种语言模型,包括 BERT、RoBERTa 和 DistilBERT,可以在不同的任务上使用。
另一个选项是 llama2,这是一个通过 GitHub 开源的基于 RoBERTa 的自主托管模型。llama2 支持多种语言模型,包括 RoBERTa、DistilRoBERTa 和 ELECTRA。
Mixtral 也是一个很有价值的自主托管LLM选项。Mixtral 使用了一种名为“Transformers”的语言模型,可以在不同的任务上使用。Mixtral 还支持多种语言模型,包括 BERT、RoBERTa 和 DistilBERT。
部署LLM
尽管自主托管的LLM可以解决一些问题,但是其他限制也需要考虑。首先,你需要一个能够运行 LL 模型的计算机和几十兆字节的存储空间。在家中使用一个普通的电脑可能不足够。
其次,你需要了解如何部署 LL 模型。这包括了解如何安装 Python、PyTorch 和 Hugging Face Transformers,以及如何编写代码来调用这些模型。
下面是一个使用 Ollama 和 Mixtral 的具体例子/步骤/指令:
使用 Ollama 的具体步骤
- 安装 Python、PyTorch 和 Hugging Face Transformers。
- 下载一个 Ollama 模型并将其存储在你的计算机上。
- 编写代码来调用 Ollama 模型,以便在使用中能够解释和应对模型的输出。
- 运行你的代码并与 Ollama 模型进行交互。
使用 Mixtral 的具体步骤
- 安装 Python、PyTorch 和 Hugging Face Transformers。
- 下载一个 Mixtral 模型并将其存储在你的计算机上。
- 编写代码来调用 Mixtral 模型,以便在使用中能够解释和应对模型的输出。
- 运行你的代码并与 Mixtral 模型进行交互。
使用 GPU 来加速 LL 模型的运行
如果你有一个具有可用的GPU的计算机,你可以在这里使用它来加速 LL 模型的运行。将 LL 模型存储在 GPU 上可以大大提高其性能。
结论
自主托管LLM是一项非常有价值的选项,它可以解决使用 ChatGPT 或者 OpenAI 服务器上运行的模型所面临的限制。在选择自主托管LLM时,你需要了解不同的选项,包括 Ollama、llama2 和 Mixtral。尽管这些 LL 模型可以使用 GPU 加速,但是如果你没有一个具有可用的GPU的计算机,你需要考虑其他选项来部署 LL 模型。